Web 端模型推理对比:ONNX vs Burn(CPU/WebGPU)
本文简单对比 onnx 与 burn 在端侧(Web端)模型推理对比,其中 burn 又拆分为 cpu 与 webgpu 方案。
模型导出
以 stagestamp 模型为例,参考 DeepLearning 在网页暗水印中的应用,为方便在端侧运行,需将 torch 模型转为跨平台部署的格式,主要分为 onnx 与 safetensors,相关区别如下:
| 特性 | PyTorch (.pt / .pth) | Safetensors | ONNX (.onnx) |
|---|---|---|---|
| 开发者 | PyTorch (Meta) | Hugging Face | 微软 |
| 序列化方式 | Pickle (Python 对象序列化) | FlatBuffers / JSON Header | Protobuf |
| 内容包含 | 权重、优化器状态、甚至任意代码 | 仅权重 (Tensors) | 计算图 + 权重 |
| 跨平台/语言 | 强依赖 Python/PyTorch | 跨语言 (Rust, Python, C++, 等) | 最强 (支持所有主流框架和硬件) |
| 主要用途 | 训练保存、断点续训、科研 | 权重分发、高效推理、Web/安全环境 | 模型部署、跨框架转换、硬件加速 |
如果你是本地跑 LM Stduio/llama.cpp 的,一般情况下,会经常看到 GGUF 或 MLX 格式,其中 MLX 又是针对 Mac 做了特殊优化,其运行时一般都有较强的 int4/int8 量化能力。
onnx
onnx 的导出代码如下:
import torch
from stegastamp.models import StegaStampEncoder;
# 加载模型
model = StegaStampEncoder(320, 320, 32)
ckpt = torch.load("model.pt", map_location="cpu")
model.load_state_dict(ckpt["encoder"])
# 导出
torch.onnx.export(
model,
(secret_tensor, image_tensor),
"encoder.onnx",
input_names=["secret_bits", "image"],
output_names=["residual"]
)
safetensors
safetensors 的导出代码如下:
import torch
from stegastamp.models import StegaStampEncoder;
from safetensors.torch import save_file
# 加载模型
model = StegaStampEncoder(320, 320, 32)
ckpt = torch.load("model.pt", map_location="cpu")
model.load_state_dict(ckpt["encoder"])
# 导出
state_dict = model.state_dict()
save_file(state_dict, "model.safetensors")
ONNX + ORT
ONNX Runtime 是 MicroSoft 主导开发的跨平台、跨语言、跨硬件的推理引擎。得益于 WebAssembly 与 WebGPU 的发展,ONNX 可以非常方便地在 Web 端运行。
import ort from 'https://g.alicdn.com/code/lib/onnxruntime-web/1.23.0/ort.min.mjs';
// 加载模型
// 线上环境,因不允许发布 onnx,所以改成了 png,都是二进制文件
const model = await ort.InferenceSession.create('./encoder.onnx');
// 输入
const bits = new ort.Tensor('float32', Float32Array.from({ length: 32 }, () => Math.round(Math.random())), [1, 32]);
const image = new ort.Tensor('float32', Float32Array.from({ length: 320 * 320 * 3 }, () => 0), [1, 3, 320, 320]);
// 推理
const output = await model.run({
secret_bits: bits,
image: image,
});
// 输出
console.log(output);
整体代码相当简单,接口也非常简单,点击查看在线效果地址 (需加载 25 MB 的文件,需耐心等待)
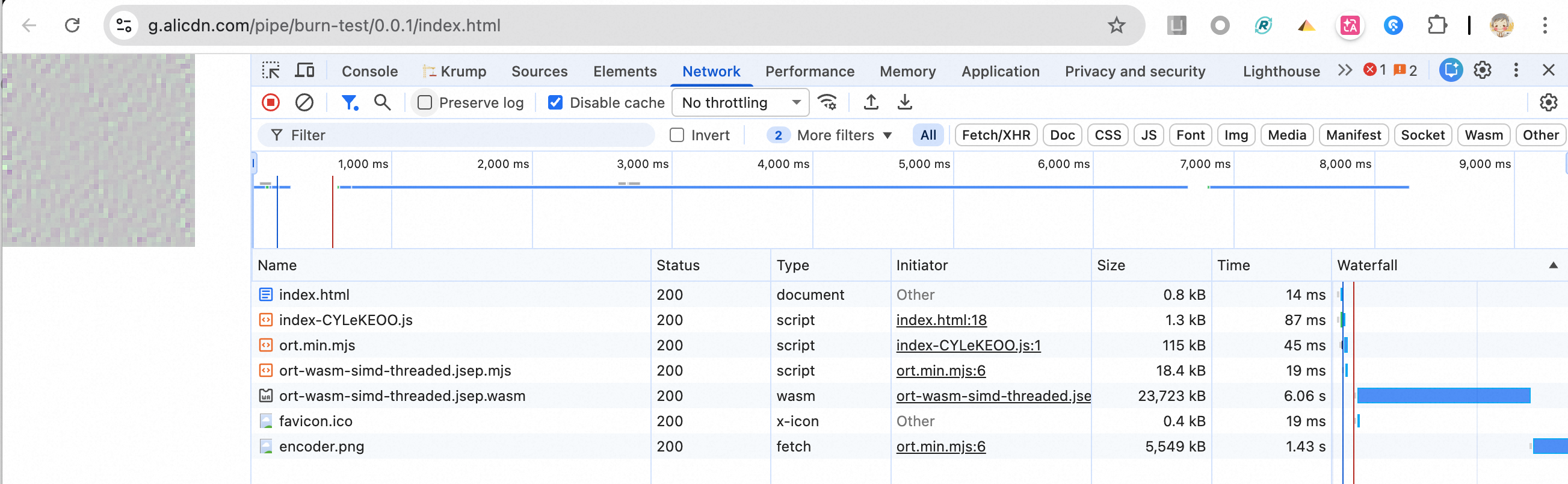
- Runtime WASM 体积有 20 MB,网络较为理想情况下,也需 6s
- 模型体积有 5 MB,网络较为理想情况下,也需 1.5s(half 精度可将半)
整体网络耗时加上推理耗时,共需 8s 左右。
Safetensors + Burn
tracel-ai/burn 是 Rust 界的 PyTorch,支持 WASM 和 WebGUPU,另外一款与其类似的是 huggingface/candle。
Burn 支持部分的 ONNX 转 Rust 代码,但经过尝试后,无法正常转换,因此无法直接使用。需将 Python 代码的模型,手动转换为 Rust Burn 代码。
Burn 模型
参考 mnist-inference-web, 模型中比如 ConvBlock 的代码如下:
#[derive(Module, Debug)]
pub struct ConvBlock<B: Backend> {
conv: nn::conv::Conv2d<B>,
activation: Option<nn::Relu>,
}
impl<B: Backend> ConvBlock<B> {
pub fn new_with_params(
channels: [usize; 2],
kernel_size: [usize; 2],
strides: [usize; 2],
padding: [usize; 2],
act: bool,
device: &B::Device,
) -> Self {
let conv = nn::conv::Conv2dConfig::new(channels, kernel_size)
.with_padding(PaddingConfig2d::Explicit(padding[0], padding[1]))
.with_stride(strides)
.with_bias(true)
.init(device);
let activation = if act { Some(nn::Relu::new()) } else { None };
Self {
conv,
activation: activation,
}
}
pub fn forward(&self, input: Tensor<B, 4>) -> Tensor<B, 4> {
let x = self.conv.forward(input);
let x = match &self.activation {
Some(activation) => activation.forward(x),
None => x,
};
x
}
}
其余模型中需要使用到的相关 Python 算子包括:
burn::nn::LinearConfig做 Linearburn::nn::conv::Conv2dConfig做 Conv2dburn::tensor::ops::InterpolateOptions做 Interpolate,上采样
等等。
Safetensors 转 Burn
因为 safetensors 存储的是张量数据,因此需要将 safetensors 转换为 Burn 模型,部分权重矩阵因习惯问题,还需做相关转置。
fn load_from_safetensors<B: Backend>(path: &str, device: &B::Device) -> ModelRecord<B> {
// 1. 读取 safetensors 文件
let data = std::fs::read(path).unwrap();
let tensors = safetensors::SafeTensors::deserialize(&data).unwrap();
...
// 辅助函数:创建 ConvBlockRecord
let create_conv_block_record = |conv_name: &str| -> ConvBlockRecord<B> {
let weight = load_tensor(&format!("{}.weight", conv_name));
let bias = load_bias(&format!("{}.bias", conv_name));
ConvBlockRecord {
conv: burn::nn::conv::Conv2dRecord {
weight: Param::from_tensor(weight),
bias: Some(Param::from_tensor(bias)),
stride: [ConstantRecord, ConstantRecord],
kernel_size: [ConstantRecord, ConstantRecord],
dilation: [ConstantRecord, ConstantRecord],
groups: ConstantRecord,
padding: ConstantRecord,
},
activation: Some(burn::module::ConstantRecord),
}
};
ModelRecord {
height: ConstantRecord,
width: ConstantRecord,
secret_dense: burn::nn::LinearRecord {
weight: Param::from_tensor(load_tensor_2d("secret_dense.0.weight")),
bias: Some(Param::from_tensor(load_bias("secret_dense.0.bias"))),
},
secret_dense_relu: ConstantRecord,
conv1: create_conv_block_record("conv1.0"),
conv2: create_conv_block_record("conv2.0"),
...
conv10: create_conv_block_record("conv10.0"),
residual: create_conv_block_record("residual"),
activation: burn::module::ConstantRecord,
}
}
随后,就可参考官方用例将其权重转为 burn 的 bin 文件,并在编译过程中,将其 include 到 Web 端。
CPU 效果
指定 burn 为 ndarray 即可走 CPU 推理。在线效果
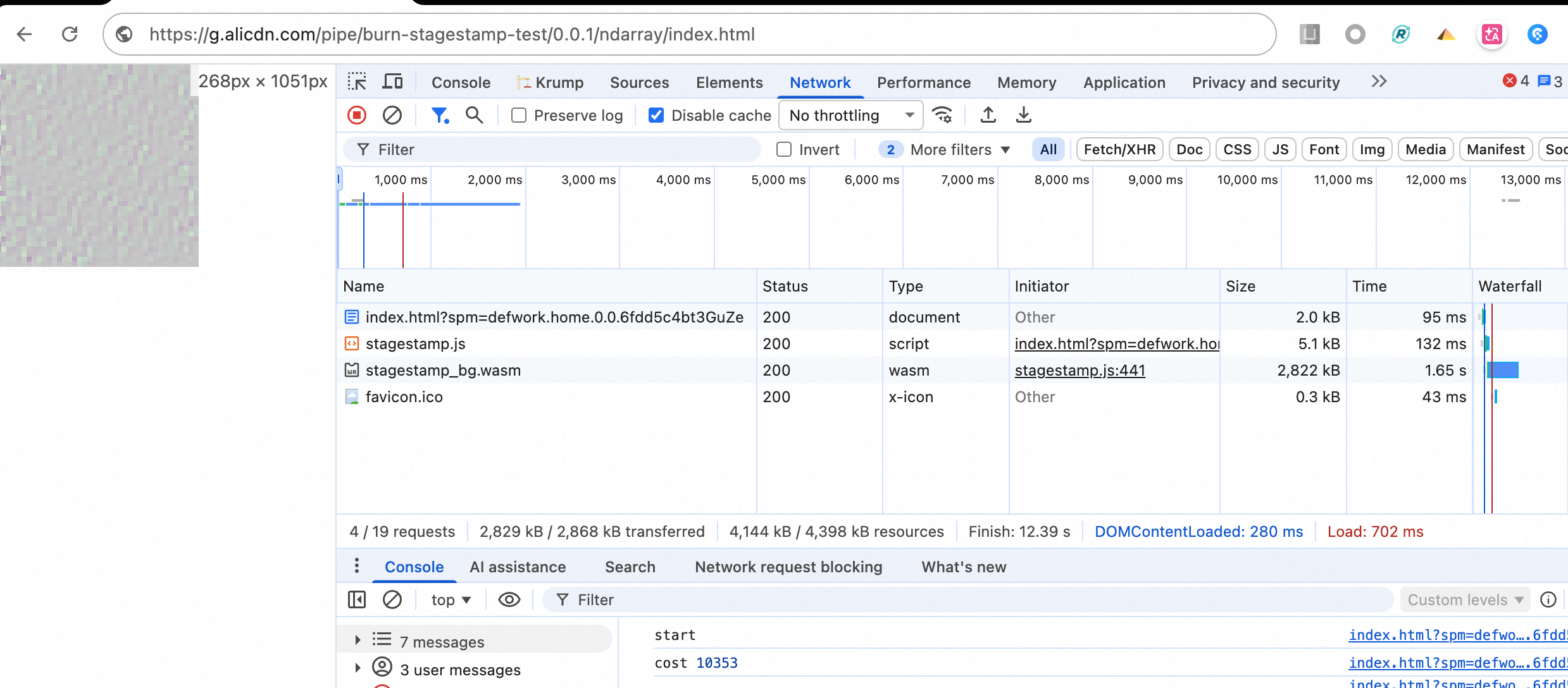
- 整体模型大小加上权重(走 half 精度,模型小一半),共 3 MB,加载时长约 1s,体积压缩非常可观;
- 推理耗时,共需 10s,时间上有些长,且会导致 Chrome CPU 跑满,拉低页面帧率及性能
- 可使用
new Worker('./worker.js', { type: 'module' });新起线程来避免上述影响
- 可使用
WebGPU 效果
指定 burn 为 wgpu 即可走 WebGPU 推理。在线效果
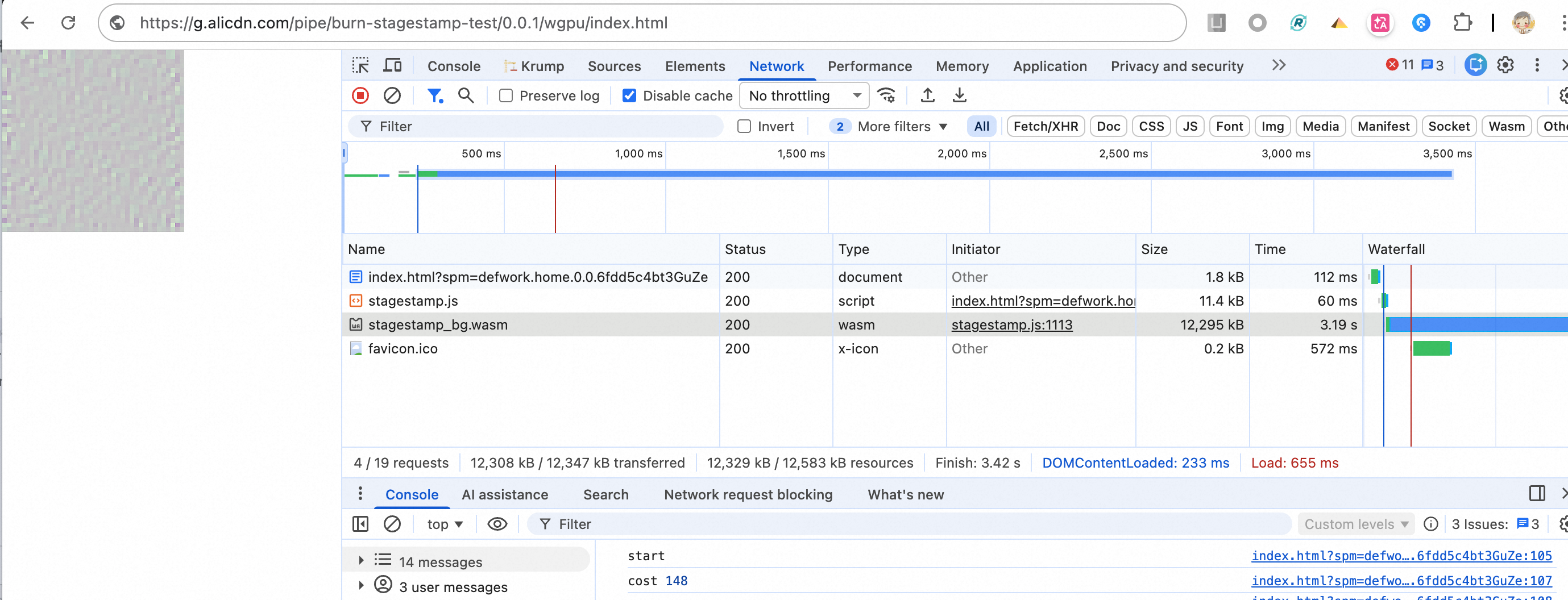
- 整体模型加上权重(走 half 精度),共 12 MB,加载时长需 3s
- 推理耗时,共需 100ms,整体较为平衡
小结
| 对比维度 | ONNX + ORT | Burn (CPU/ndarray) | Burn (WebGPU/wgpu) |
|---|---|---|---|
| 总体积 | ~25 MB (WASM 20MB + 模型 5MB) | ~3 MB (模型+权重,half精度) | ~12 MB (模型+权重,half精度) |
| 加载时长 | ~7.5s (WASM 6s + 模型 1.5s) | ~1s | ~3s |
| 推理耗时 | ~200ms | ~10s | ~100ms |
| CPU占用 | 低 (GPU加速) | 高 (跑满CPU,影响页面性能) | 低 (GPU加速) |
| 编码难度 | ⭐ 简单 | ⭐⭐⭐⭐ 困难 | ⭐⭐⭐⭐ 困难 |
| 模型转换 | 直接导出 ONNX | 需手动转写 Rust 模型代码 | 需手动转写 Rust 模型代码 |
| 综合评价 | 体积大但易用 | 体积小但慢且影响性能 | 最佳平衡方案 |
- ONNX + ORT:最容易上手,API 简单,但体积较大(25MB,其基础运行框架有 20MB),首次加载慢,可用于快速验证/原型
- Burn CPU:体积最小(3MB,仅包括模型需要的算子),但推理慢(10s),在不支持 WebGPU 下可结合 Worker 考虑
- Burn WebGPU:较为平衡方案 - 体积适中(12MB),推理快(100ms),但 python 转 rust 模型的工作量需考虑
另外:
如果模型大小已远远大于 20MB,则建议使用 ORT,因为加载时长已不再是核心考虑因素。
如果对性能有极致的优化诉求,建议 burn,可干预的手段更多。