客户体验追踪中暗水印的技术选型
客户体验追踪中暗水印的技术选型,本文通过对比现有 DWT-DCT-SVD、纯网页 JS 方案、Deep Learning-based 算法方案,尝试找出适合网页暗水印的技术方案。
背景
作为基础性的交易体验技术团队,需经常处理客户反馈过来的问题,而如何定位、排查问题,成为了解决、追踪客户体验的首要问题。
客户的问题反馈,经常是工单中、聊天框的一张截图,虽然会有文本描述,但信息量最为丰富的,还是用户的截图。如何通过一张图片,定位到用户、页面地址、接口请求数据,成为了最大的挑战。而暗水印成了这一整个客户体验追踪过程的核心技术能力。
技术选型
如何在网页中添加暗水印,使得用户在截图之后,发送给技术排查问题的图片,能直接识别出有关编码信息,社区中有如下实践:
DWT-DCT-SVD
参考 基于 DWT-SVD 鲁棒盲水印算法研究、基于DWT-DCT-SVD的彩色图像零水印算法 [1][2],其方案主要原理如下:
将图像从 RGB颜色空间转换到 YCbCr颜色 空 间,然后对亮度分量(Y)进行一层离散小波变换(DWT),取其低频子带进行分块离散余弦变换(DCT),并且对每个分块进行奇异值分解,使分解得到的奇异值作为图像的特征来构造零水印。
该方案针对图片文件有较好的鲁棒性,能对抗剪切、中值滤波、JPEG 压缩等,但在网页暗水印的场景下,无法提前获取网页截屏的图片,做相关的前置嵌入(或计算、传输成本过高),也无法从技术层面,在用户截图后,做相关后置操作。所以,使得该方案在此场景下,无法进行有效的落地。
其相关的社区实现方案可参考:ShieldMnt/invisible-watermark [3]
纯网页方案
更为直接的方案,则是在明水印的基础上,尽可能低地调整用户的可见性,从而实现类似暗水印的结果。如下所示:
| 暗水印图片 | 显性化后水印图片 | 水印信息 |
|---|---|---|
| 下面👇有张含有水印灰色图片 | PS 可通过图像中调整色阶显现 | - |
 |
 |
19Z35HW6 |
该方案整体没啥问题,但整体鲁棒性较差,特别是图片上传各种平台、或各种及时通讯软件中,发送图片的默认行为都有相关压缩算法,整体效果就会变成:

像素化字体方案
经过图片压缩,相关的水印文字就会像素化,由此可以非常自然延展到使用像素字体来替代默认字体,来提升整体的抗压缩能力。
所以,参考 TakWolf/fusion-pixel-font [4],裁剪了一套仅包含数字的像素字体,字体的好处除了可读性之外、还自带纠错能力。
但尝试之后,整体抗压缩能力,依旧不够理想。如下

Deep Learning 方案
参考 HiDDeN、StegaStamp、TrustMark [5][6][7],特别是 2018 的 HiDDeN 的论文表明:神经网络可以学会利用不可见的扰动来编码大量有用的信息,这种能力可用于数据隐藏任务。当联合训练编码器和解码器网络,给定输入消息和载体图像,编码器生成视觉上无法区分的编码图像,而解码器可从中恢复原始消息。
而且,模型能够在存在高斯模糊、像素级丢弃、裁剪和JPEG压缩的情况下,重建编码图像中的隐藏信息。这使得网页暗水印有了新的尝试路径,且其鲁棒性可通过大量的训练进行对抗。
DL 方案选型
ScreenMark
参考 HiDDeN、StegaStamp、TrustMark、VINE、ScreenMark [5][6][7][8][9] 相关论文,其中和网页暗水印最为契合的,是 ScreenMark。论文的出发点也是对屏幕级别的内容做相关的水印嵌入,而非对传统的图片文件做相关水印嵌入,所以其使用场景是一致的。
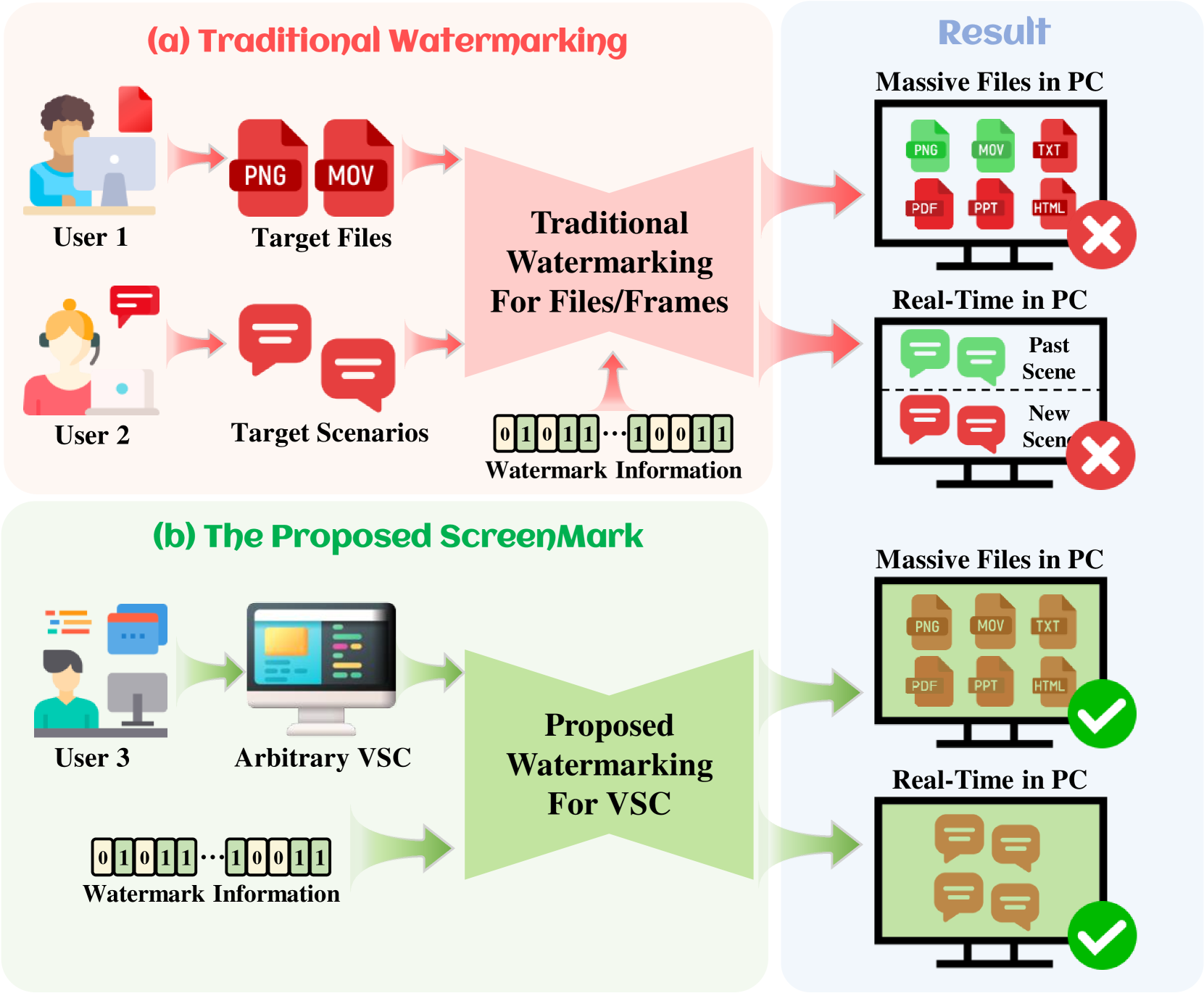
但比较可惜,论文作者并没有开源相关模型的实现,所以只能先 Hold,优先参考其他方案。
VINE
VINE 有相关实现,重点对图片编辑做了相关训练,对网页暗水印场景,因为未做相关训练,整体效果并不理想。且参考 训练资源,全量的训练,需 8 张 A100 GPUs,训练需持续一周。对于现有手上的资源,其训练算力是个巨大的障碍,故基本可以放弃。
HiDDeN
HiDDeN 官方实现是 lua 写的。网络由于提出较早,且比较经典,社区有较多可用的实现,基于 ando-khachatryan/HiDDeN [10] 做了简单的测试,总体的参数规模在 40W 左右, 使用 Mac GPU 即可做简单的训练,经测试,整体的鲁棒性较差,故放弃。
其他
其他稍近的模型和论文,因时间问题,暂未纳入实际测试环节,包括 MBRS[13][14]、PIMoG [15][16]、DWSF[17][18]、TrustMark[7][19] 等。后续需继续深入测试、评估。
StegaStamp
StegaStamp 是另外一个较为经典的 DL 模型,社区开源项目也较多, 官方实现是基于 tensorflow 的 tancik/StegaStamp[11],找了一个pytorch 的版本 jsrdcht/StegaStamp-pytorch [12]
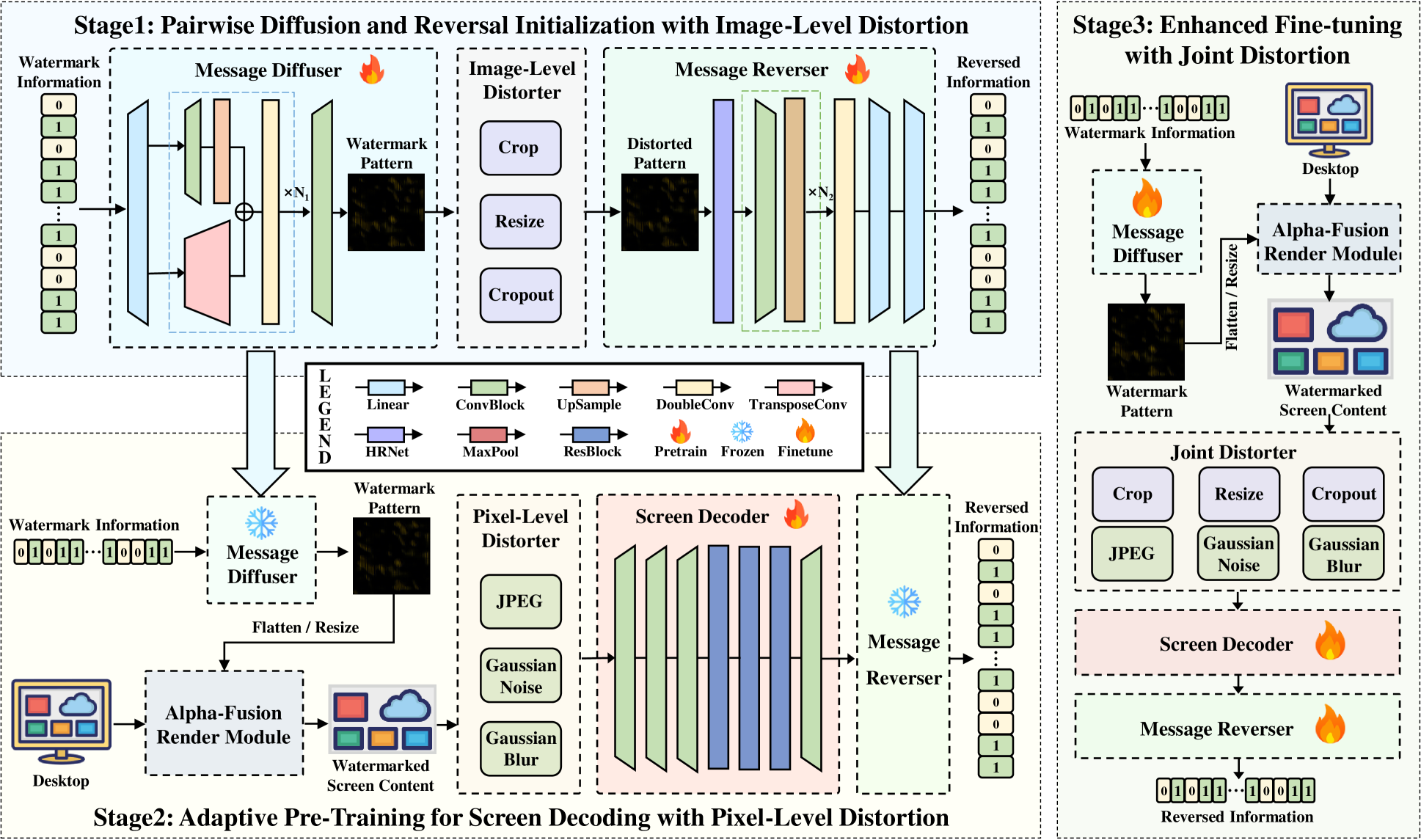
模型架构
对开源实现做网页暗水印场景的相关适配后,整体改动后的模型架构大致如下:
以下为简易示意图,细节未做处理。
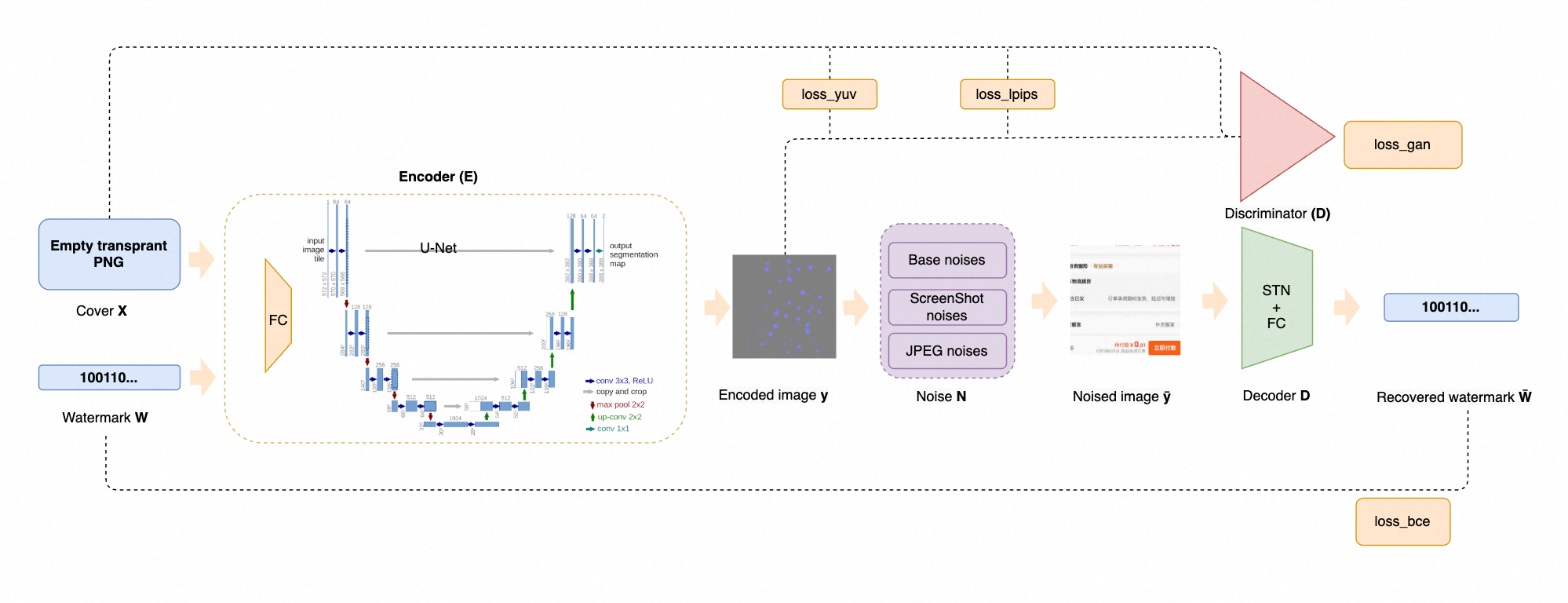
相关具体改动点:
- 开源实现为 400 * 400,本地测试项目整体图片 size 为 320 * 320,后续可考虑 300*300(方便被 1/2/3/4 整除,因移动屏幕设置有上述 Device Pixel Ratio);
- secret size 为 32,提升准确率和减少失败率(暂未测试长字节 + 长纠错码的 BCH 方案,后续需验证);
- 输入始终为透明图,方便后续做 alpha 覆盖;
- noise 层,重点模拟截图效果与 JPEG 压缩效果,且 JPEG 需选用可微分的库,方便反向传播与梯度下降;
模型训练
- 数据集的问题,在此场景下,无需标注且数据量的生产和验证(即水印生成和验证)较为简单
- 背景图选用无线订单详情,由于截图是 3 倍图,所以可再随机裁剪 100 次作为 noise 背景
- 因资源限制,仅能使用 PAI 平台的 V100 GPU
以 batch_size 为 8 (太大超 GPU 内存),epoch 为 14w 的情况下,训练时间约为 4 小时。
整体的 loss_global 曲线如下:
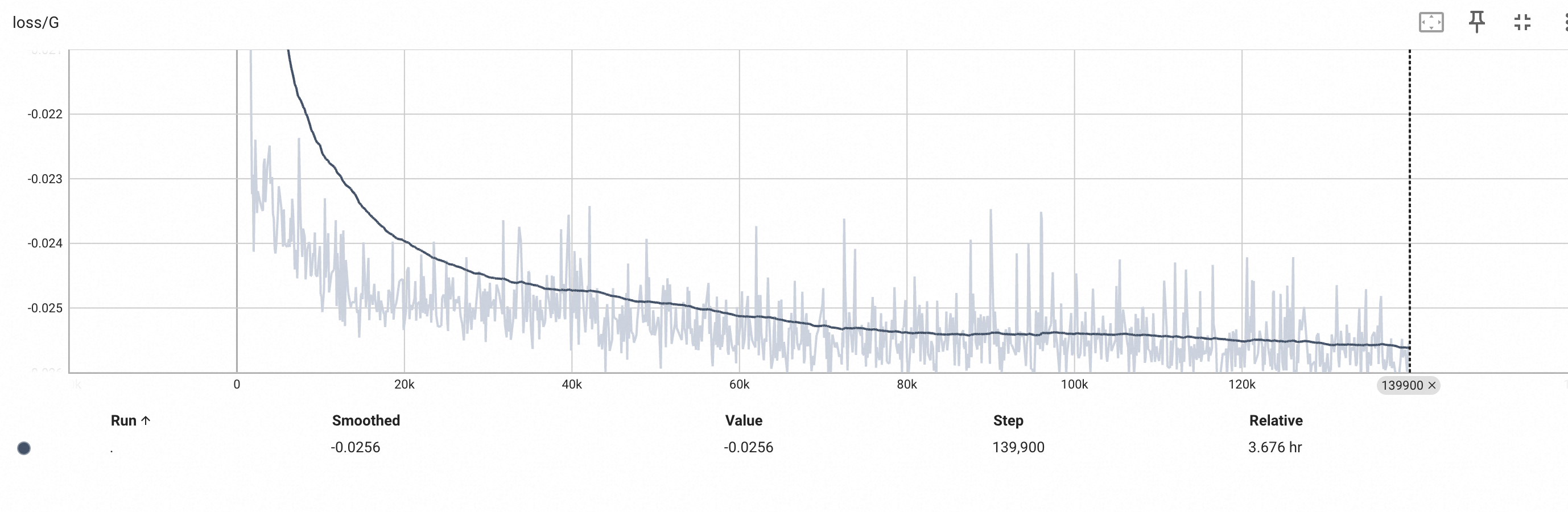
大部分的 loss 突变,是因为 JPEG 的压缩等随机 noise 造成的
效果
测试脚本如下:
# 将 pipe 字符串嵌入的图片水印中
$ python -m stegastamp.encode_image --model $MODEL_PATH --save_dir ./images_output --secret pipe
# 模拟截图压缩
$ ffmpeg -v quiet -i ./images_output/empty_residual_noised.png -c:v mjpeg -qscale:v 51 -update 1 -frames:v 1 ./images_output/empty_residual_noised.jpg -y
# 解码压缩后的图片
$ python -m stegastamp.decode_image --model $MODEL_PATH --image ./images_output/empty_residual_noised.jpg
[0, 1, 1, 1, 0, 0, 0, 0, 0, 1, 1, 0, 1, 0, 0, 1, 0, 1, 1, 1, 0, 0, 0, 0, 0, 1, 1, 0, 0, 1, 0, 1]
pipe
# 最终输出 pipe 正确
| 背景图 | 残差图 | 截图 | 压缩图 | 水印显示 |
|---|---|---|---|---|
| 28k,PNG | 15k,PNG | 截图 31k,PNG | 压缩后 5k,JPG | 压缩后的显现化 |
 |
 |
 |
 |
 |
后续工作
-
验证 BCH 纠错机制与概率匹配的整体准确率,找到最佳平衡点。
-
参考 screenmask 架构,做如下工作:
- 尝试引入 diffusion 扩散模型对原有的 U-Net 做相关优化
- 在对 diffusion 模型冻结的基础上,单独引入 Screen Decoder,做相关的自适应训练学习
-
加入失真的联合强化训练学习
- 对 MBRS(2021)[13][14]、PIMoG(2022)[15][16]、DWSF(2023)[17][18]、TrustMark(2023)[7][19] 做相关调研
结论
本文从网页暗水印作为客户体验的追踪的核心手段出发,重点测试了基于 Deep Learning 的 StegaStamp 方案,通过背景图、JPEG 压缩等 noise 手段,对最终的结果进行验证,初步证明该方案的可行性。为后续其他方案的优化、落地,提供了较为明确的方向性指导。
参考
- 基于 DWT-SVD 鲁棒盲水印算法研究
- 基于DWT-DCT-SVD的彩色图像零水印算法
- ShieldMnt/invisible-watermark
- TakWolf/fusion-pixel-font
- HiDDeN: Hiding Data With Deep Networks
- StegaStamp: Invisible Hyperlinks in Physical Photographs
- TrustMark: Universal Watermarking for Arbitrary Resolution Images
- VINE: Robust Watermarking Using Generative Priors Against Image Editing: From Benchmarking to Advances
- ScreenMark: Watermarking Arbitrary Visual Content on Screen
- ando-khachatryan/HiDDeN
- tancik/StegaStamp
- jsrdcht/StegaStamp-pytorch
- MBRS : Enhancing Robustness of DNN-based Watermarking by Mini-Batch of Real and Simulated JPEG Compression
- jzyustc/MBRS
- PIMoG: An Effective Screen-shooting Noise-Layer Simulation for Deep-Learning-Based Watermarking Network
- FangHanNUS/PIMoG-An-Effective-Screen-shooting-Noise-Layer-Simulation-for-Deep-Learning-Based-Watermarking-Netw
- Practical Deep Dispersed Watermarking with Synchronization and Fusion
- bytedance/DWSF
- adobe/trustmark